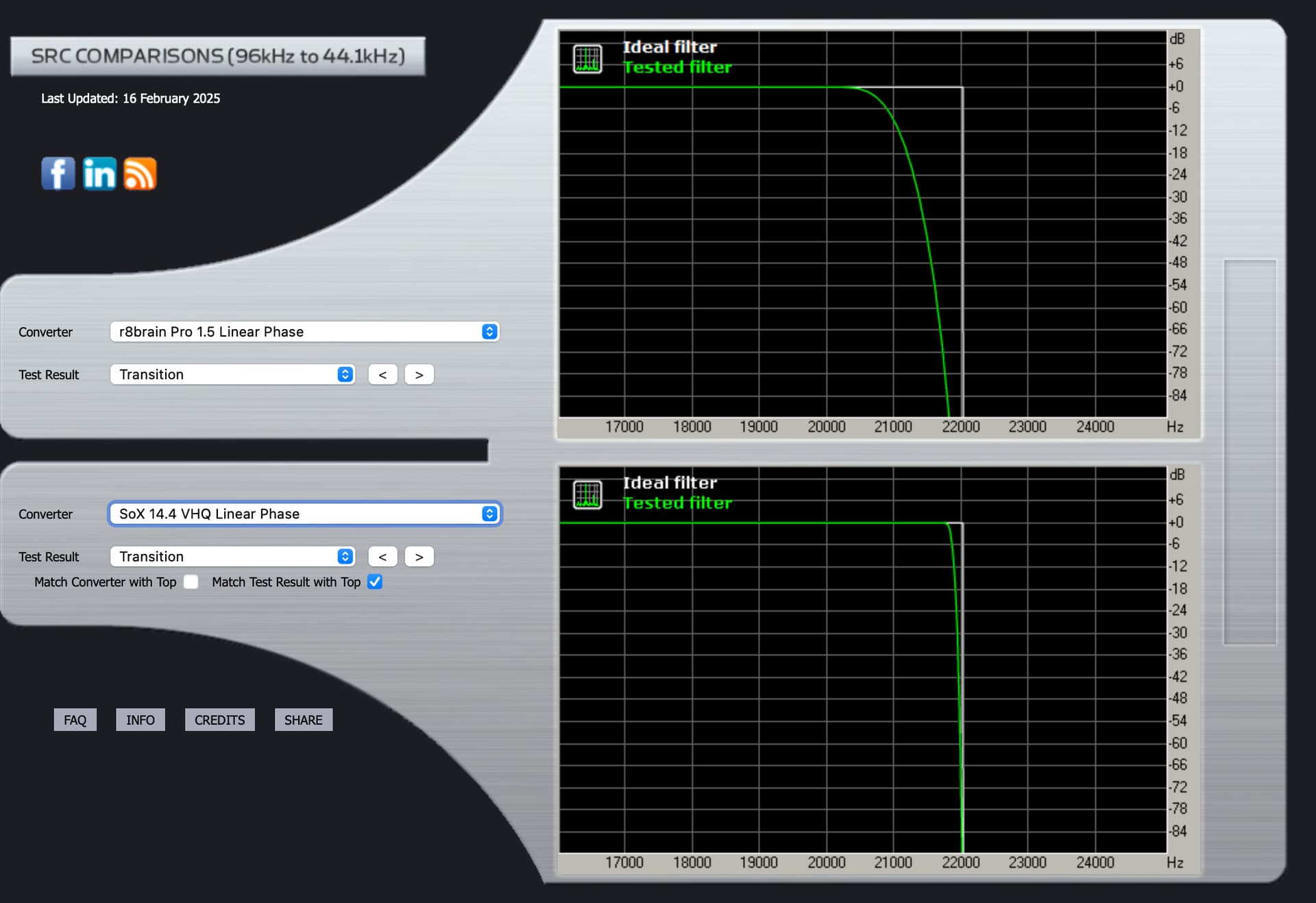
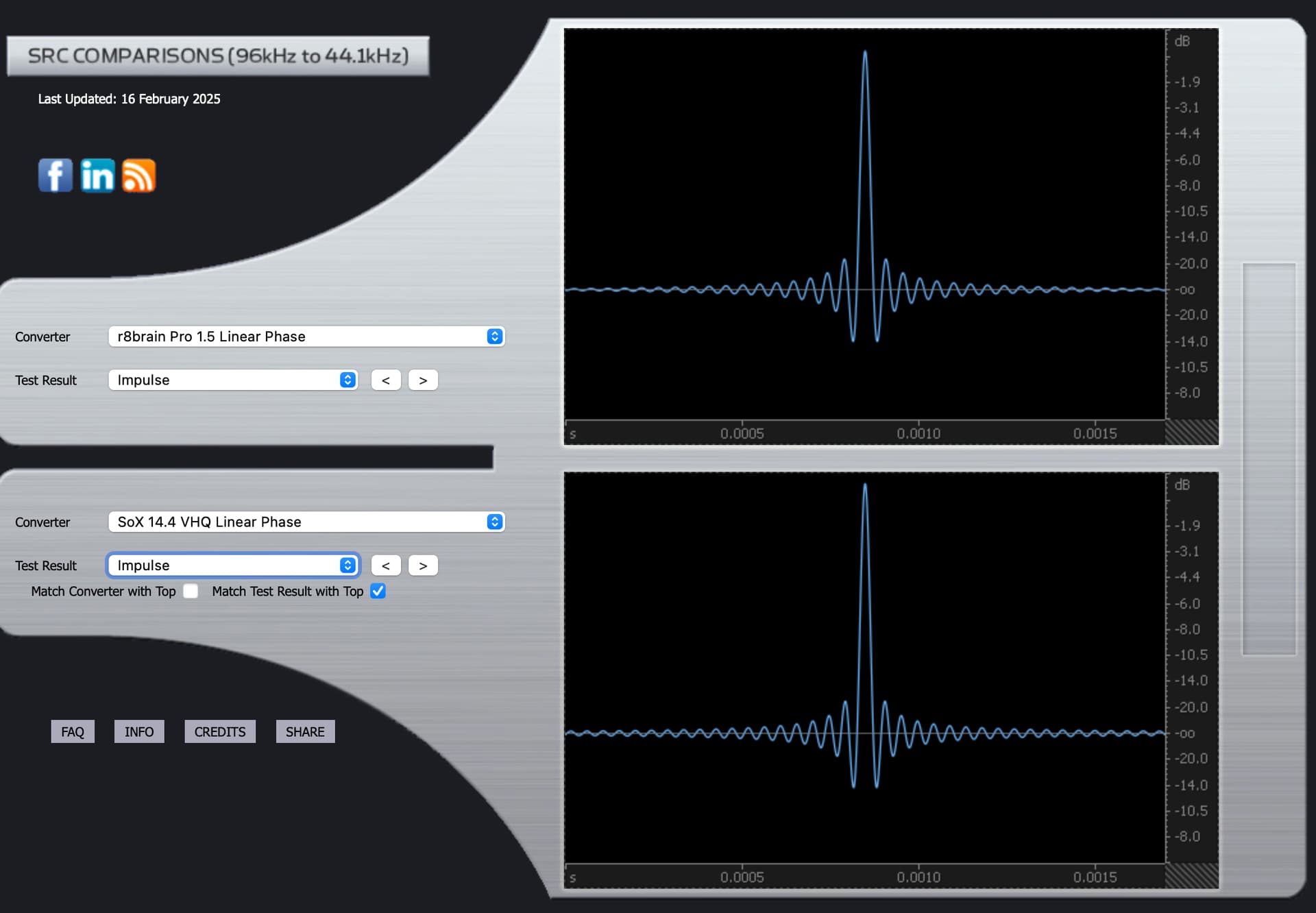
If you could provide the impulse response and transition graphs, using Sox minimum phase as you have, but changing R8Brain to the linear phase version, that would be great. ![]()
I’d like to add that, while I personally opt to focus on acoustic treatment, imo Dirac (and other DSP) are entirely valid methods to tackle uneven room acoustics. I do use DSP for movies. With my latest acoustic treatments, however, I find my Yahama receiver to sound better playing surround SACDs in Pure Direct mode, without any PEQ or DSP. But acoustic treatment isn’t cheap and takes a lot of time (and a trained ear) to get right. I have a calibrated studio with near-flat frequency response at the listening position verified with a professional measuring microphone. In my living room I opted to go mostly by ear. For which, as I mentioned, I took multiple years, placing an absorber or diffusor, tuning its angle, changing its bended shape, things like that.
Dirac can save both money and a LOT of time!
1 Like
r8brain Linear Phase:
(I assume you mean to compare to my SoX “Intermediate Phase”, as it is probably closest to my preferred 66% setting.)
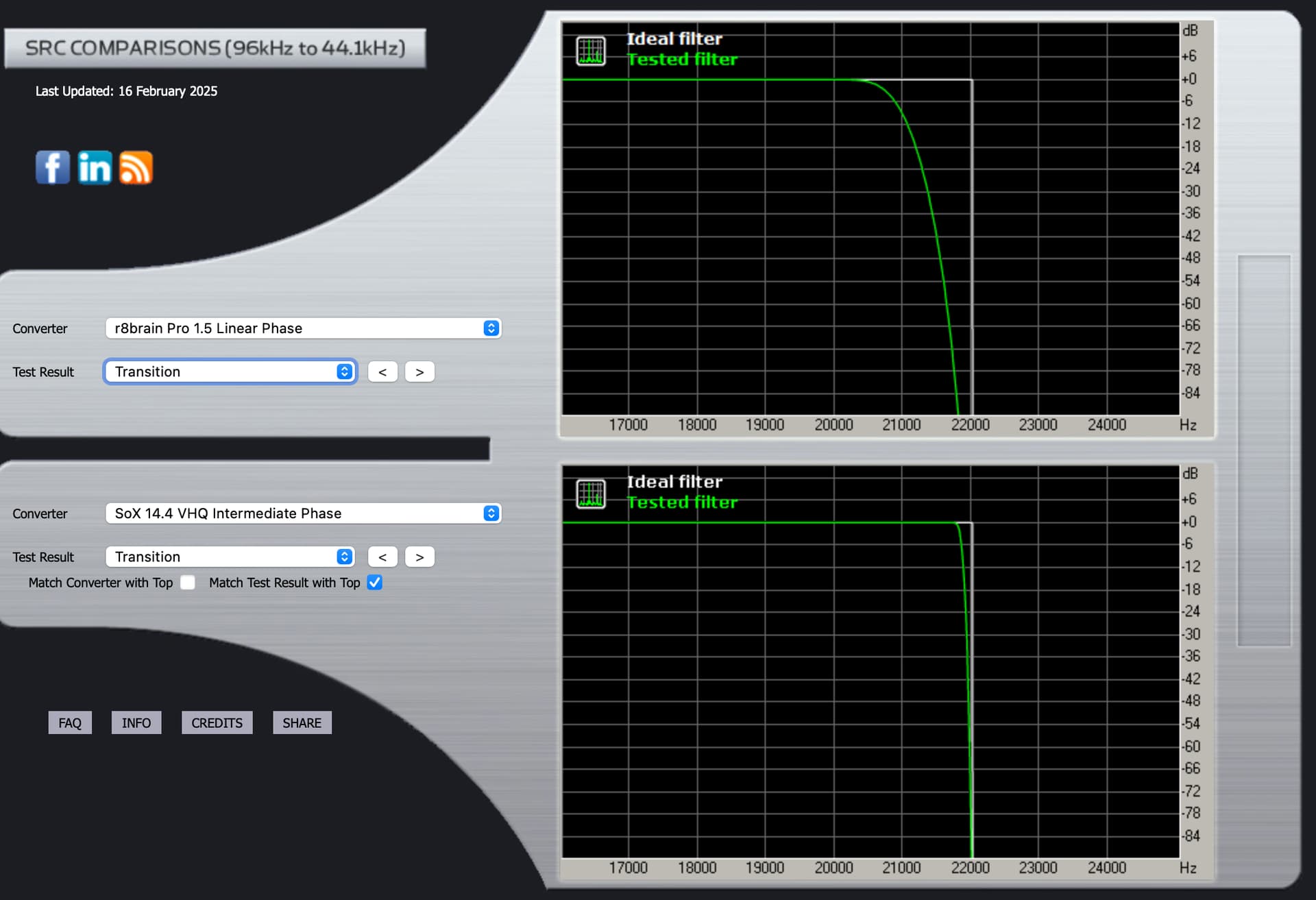
Transition graph SoX Intermediate.
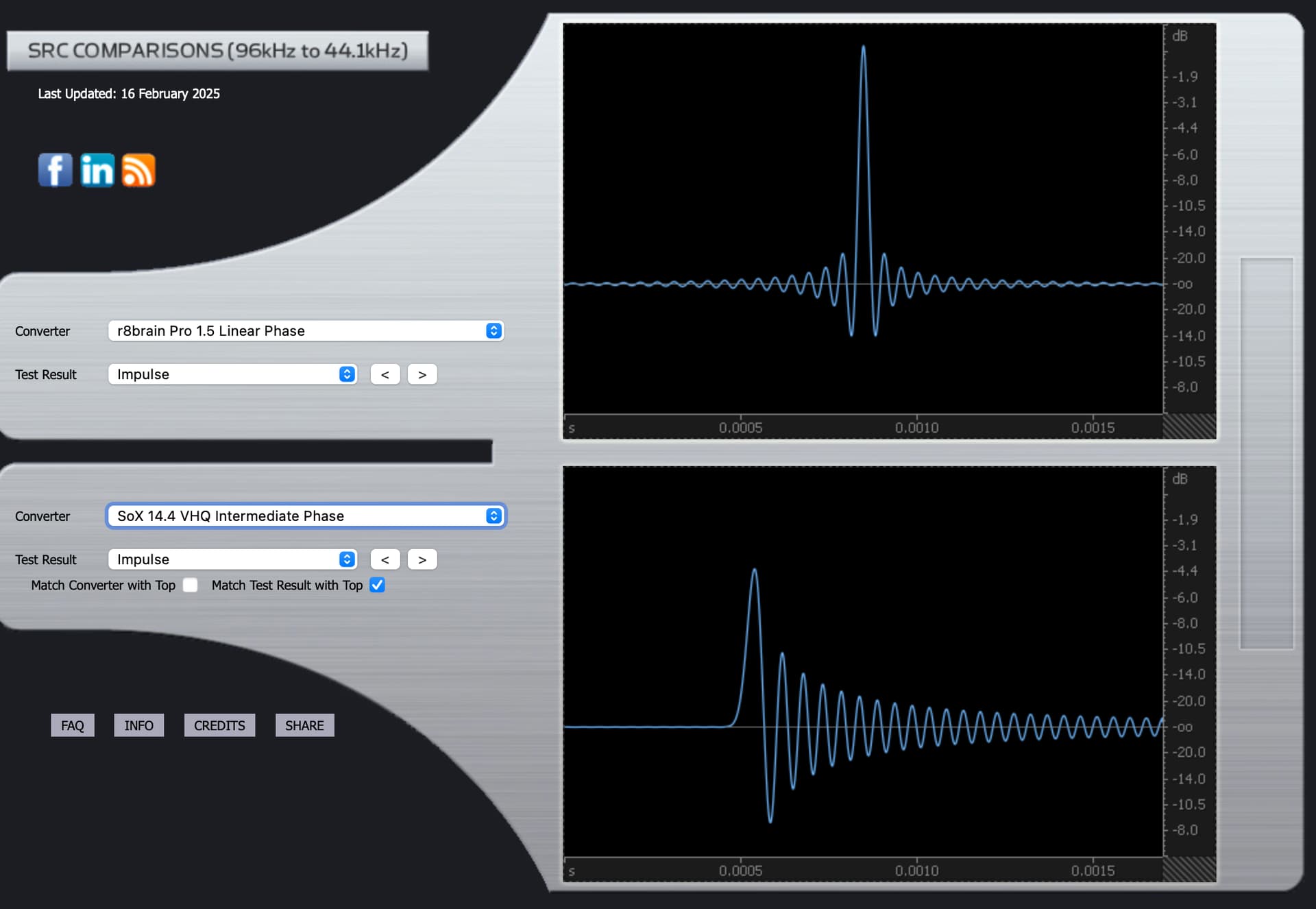
Impulse response SoX Intermediate.
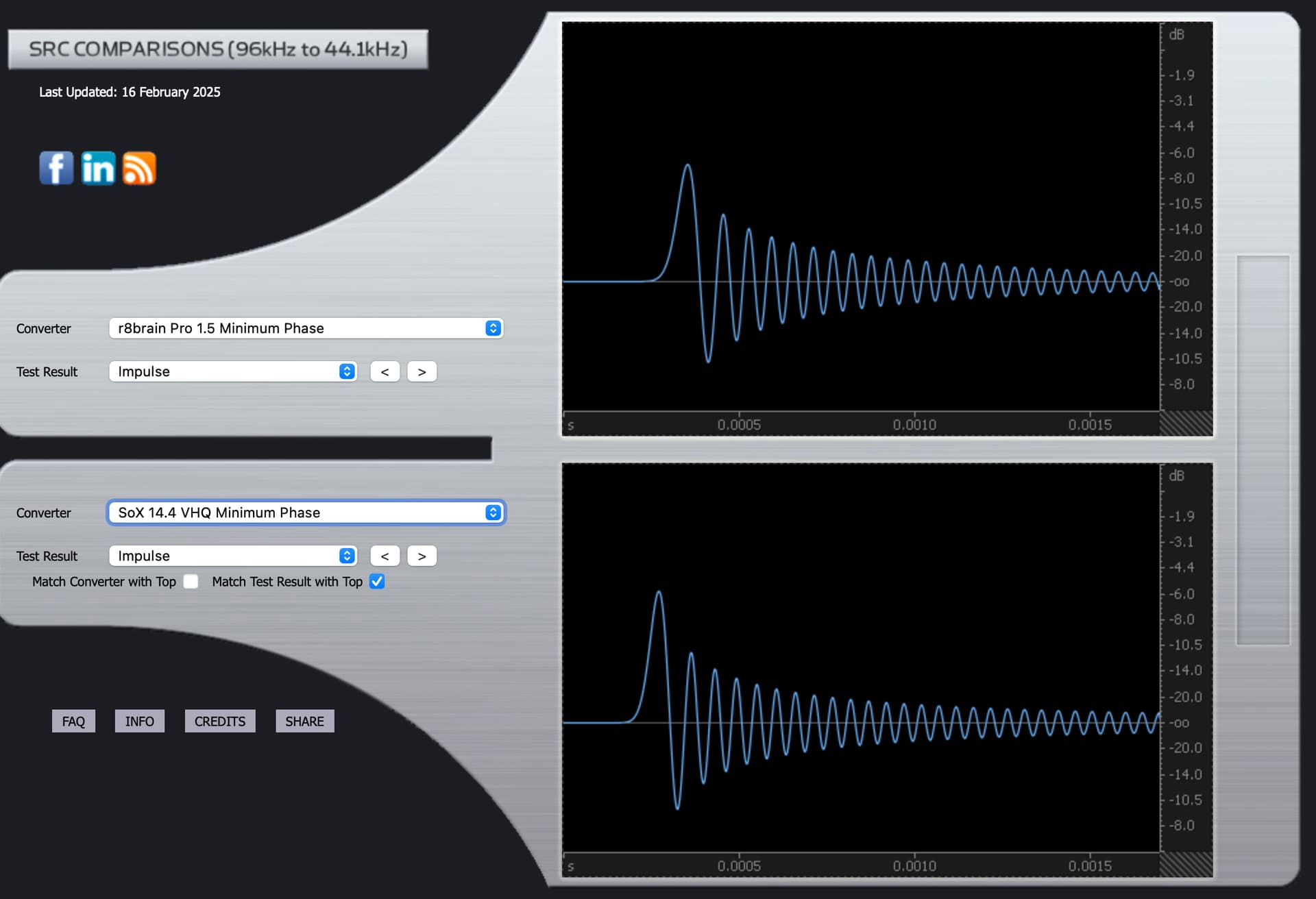
r8brain Minimum Phase:
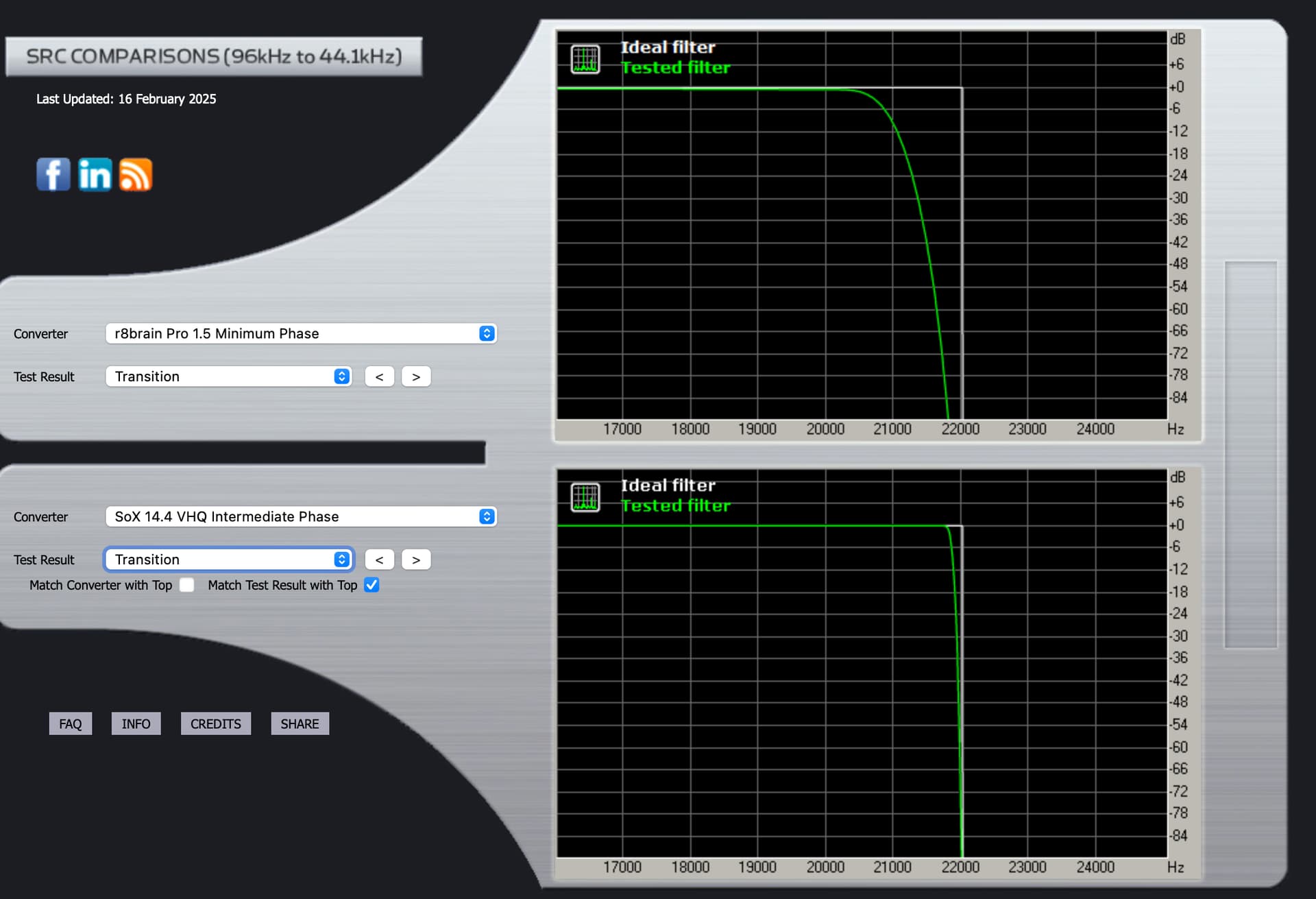
Here’s the transition graph for SoX “Intermediate Phase” which likely comes closest to my 66% setting.
Here it is for SoX “minimum phase”.
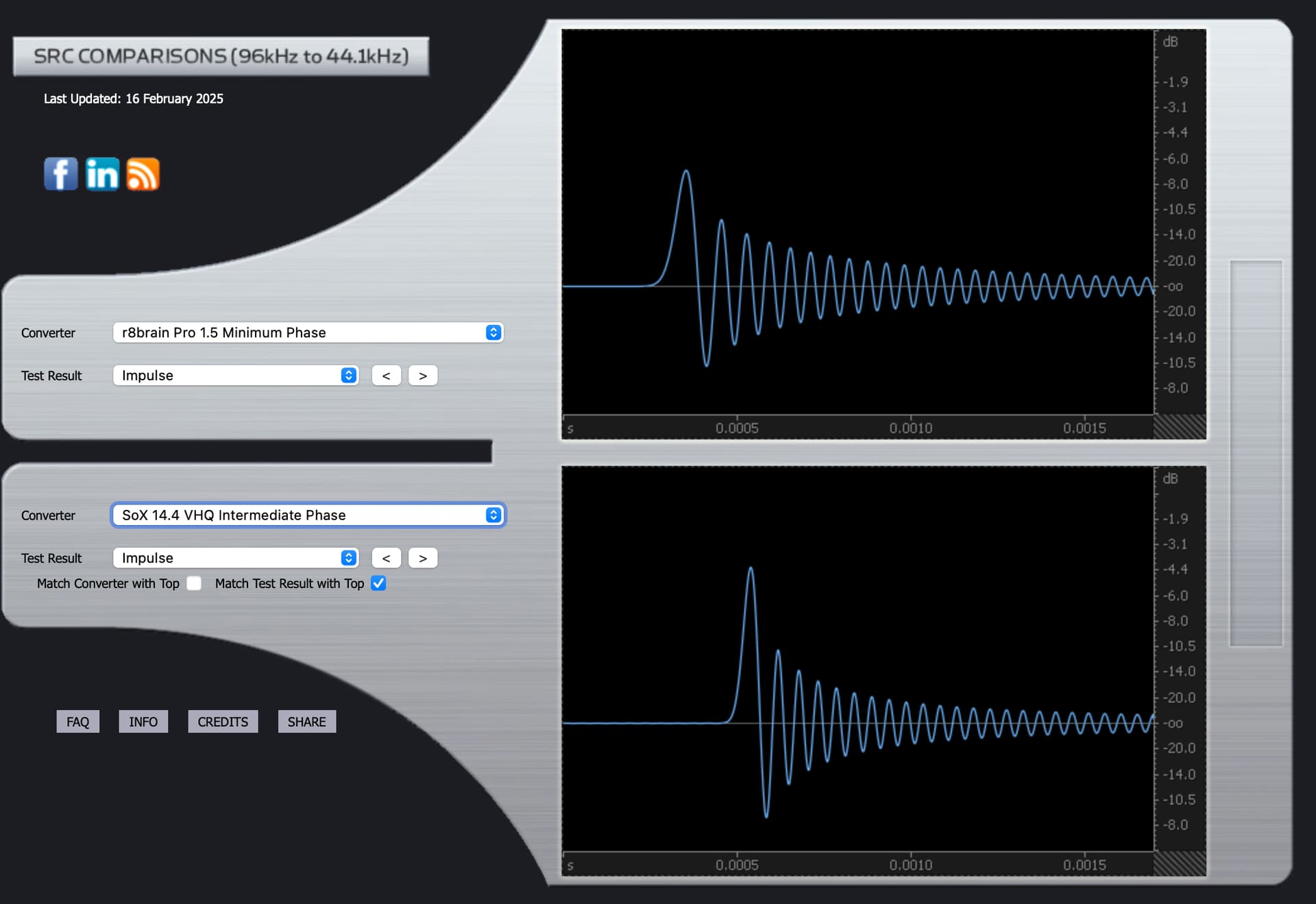
The Impulse graph for SoX Intermediate.
The Impules graph for Sox
Fascinating!
I just discovered that there are newer r8brain versions and a SoX “High Quality (Aliasing Enabled)” setting. We should definitely also compare these:
rBrain Pro 2.12 (Precise Linear Phase)
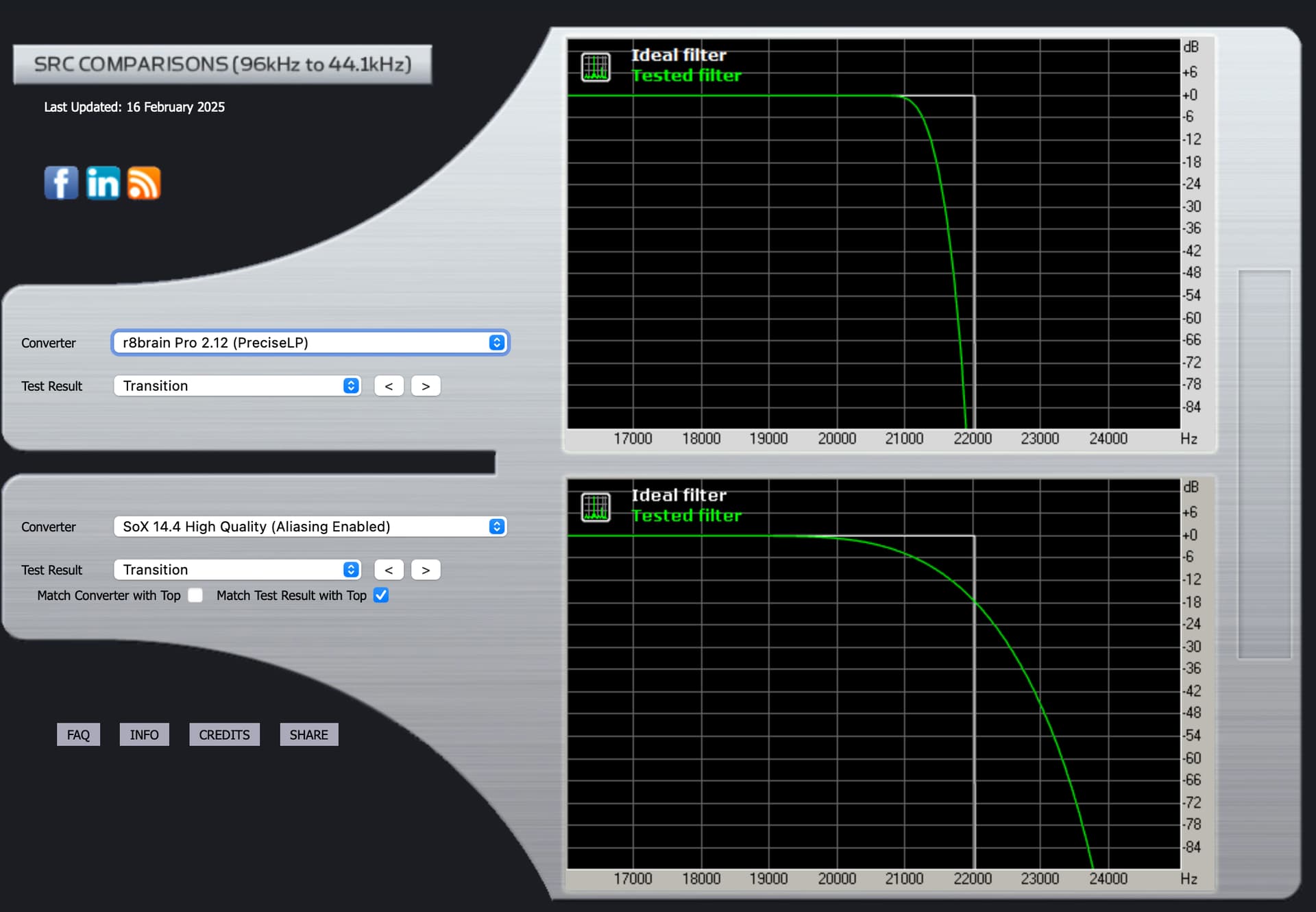
Transition
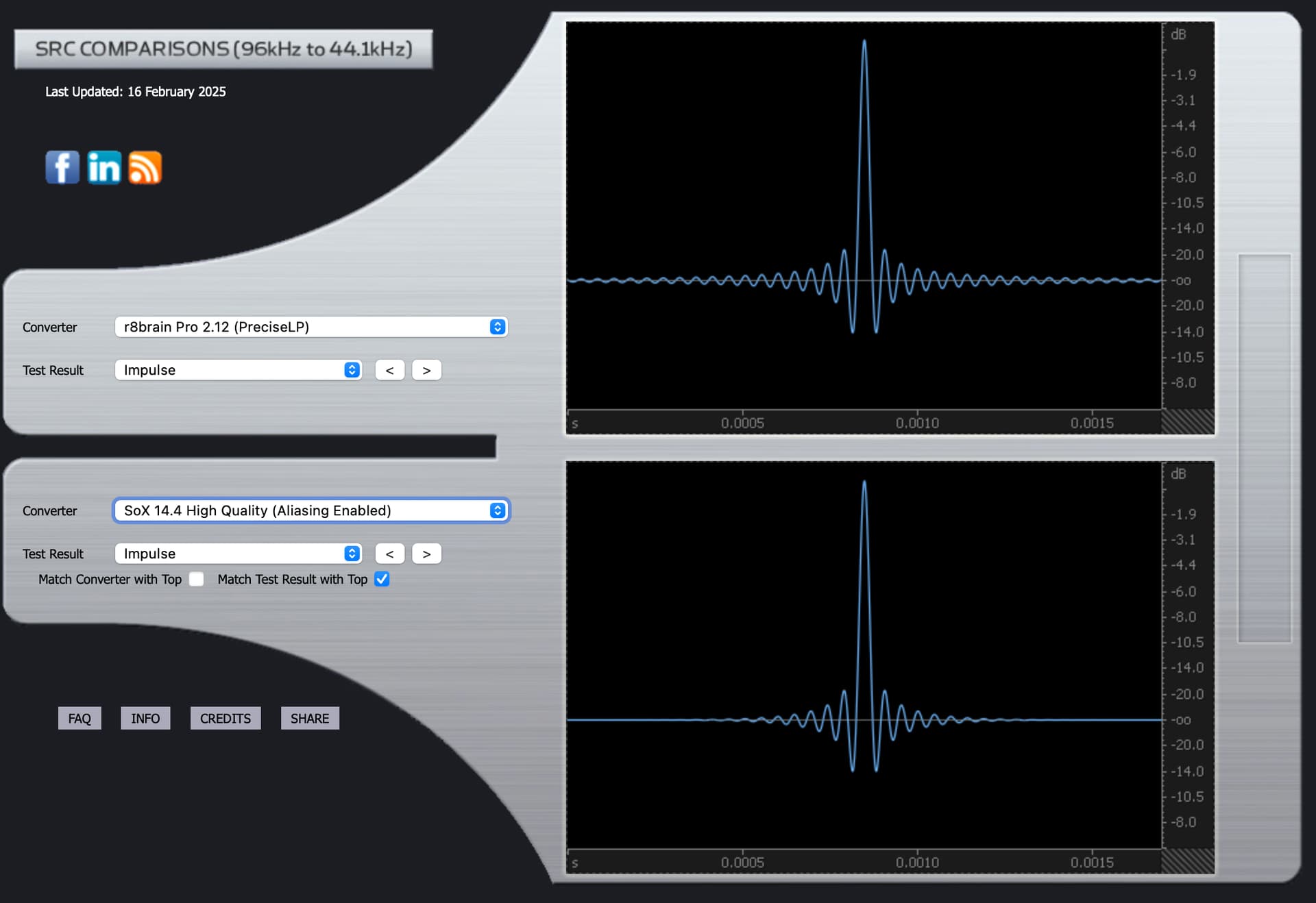
Impulse
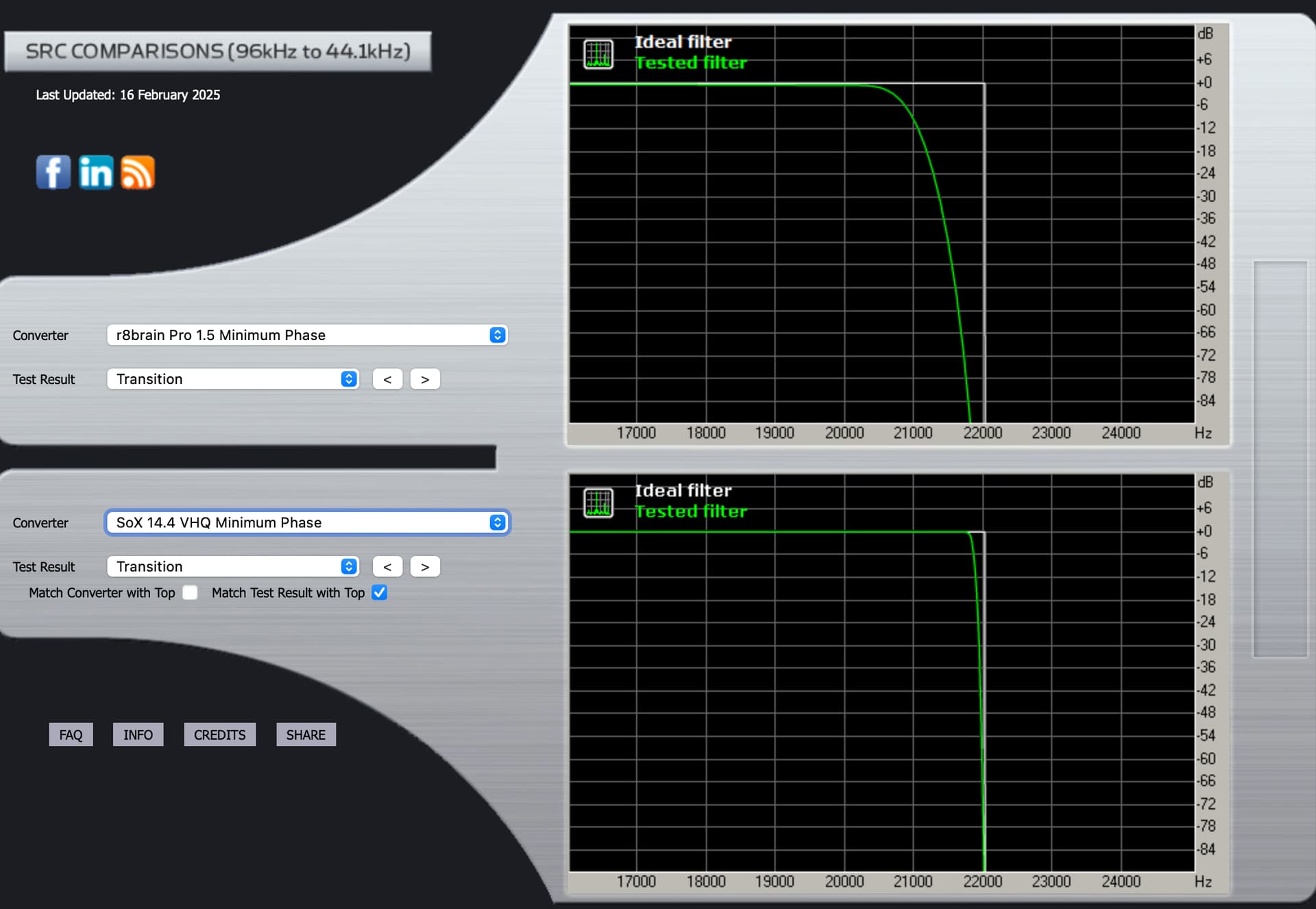
rBrain Pro 2.12 (Precise Minimum Phase)
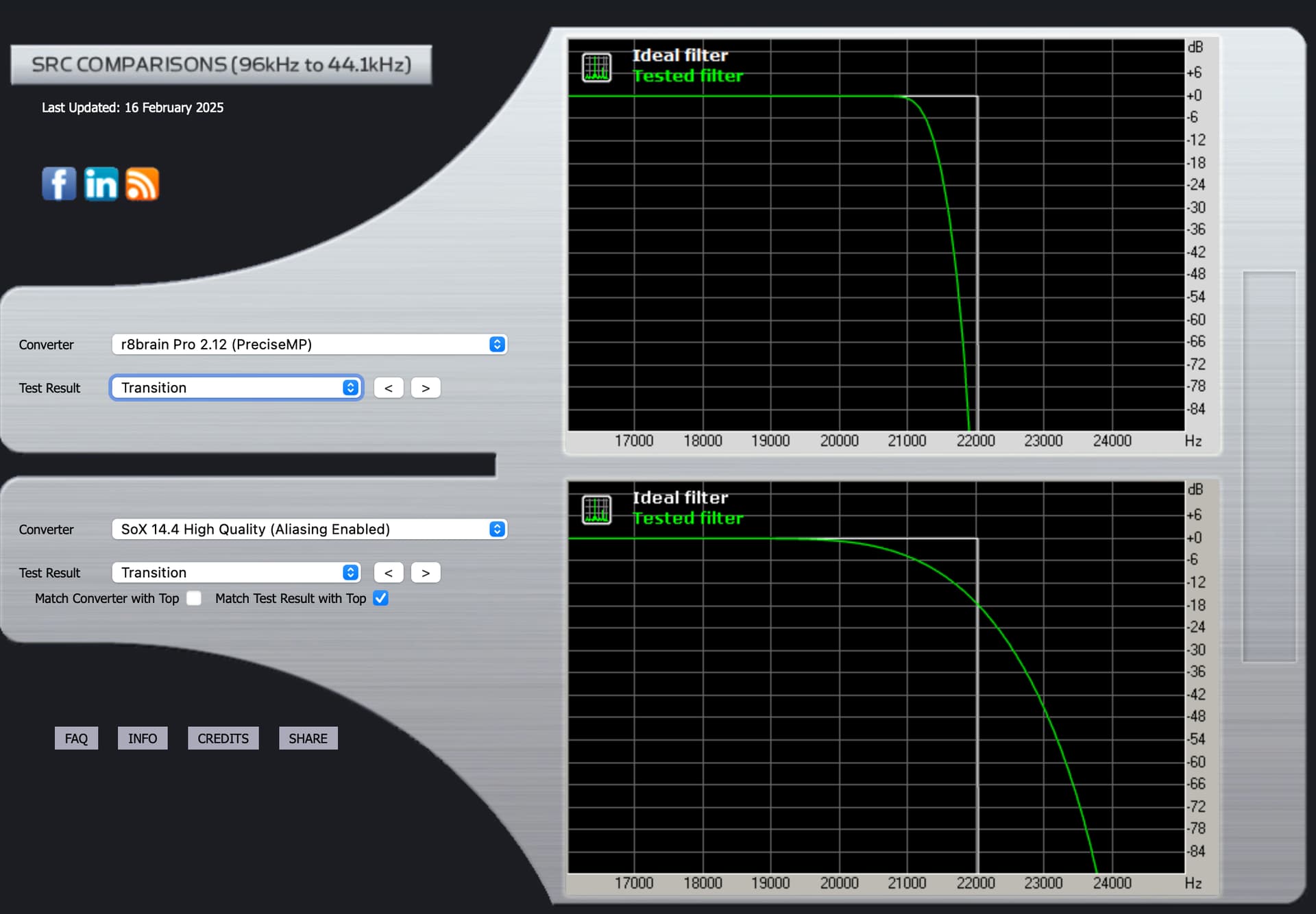
Transition
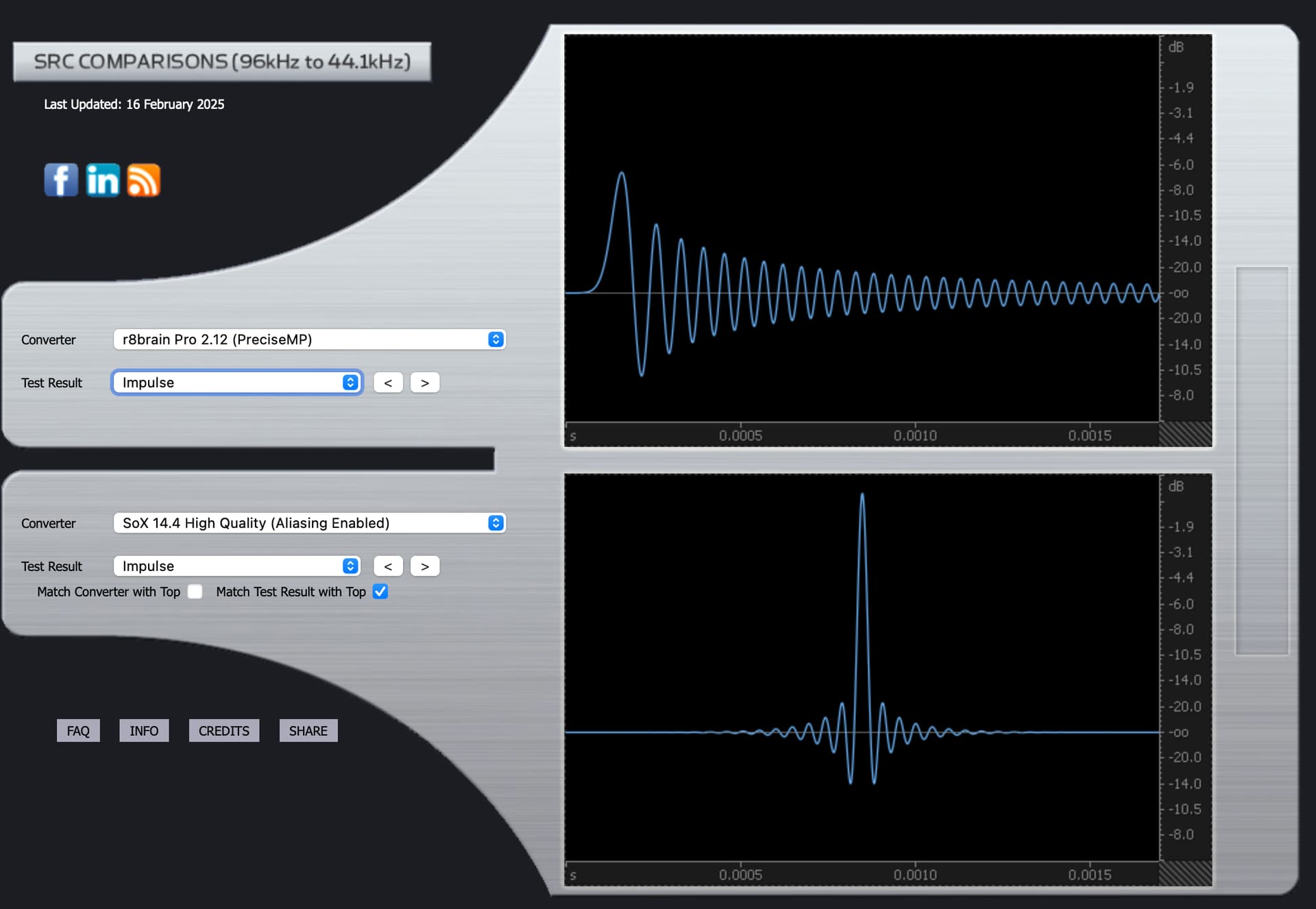
Impulse
I am not technical educated. What’s the exact purpose of these images? I get exactly the same, so what can we do with these with regard to my set up?
@mhsmit @Jud @OffRode @Amarok1969
You will notice in all instances of Liner Phase response, the reduced stop band ringing post Fc … In the Minimum Phase response, the post Fc ringing amplitude level is high and extended… This noise gets folded back… You will notice that there is no parametric adjustment for the attenuation of stop band noise in the SoX algorithm, however this stop band attenuation control exists in the r8Brain algorithm… This is the trade-off… The level of stop band leakage, can be construed in the audition, as increased upper frequency detail, where it is actually out of phase noise and in worse-case, this folded-back noise skews the frequency balance due to doppler-effect…
I prefer the ability to manage the stop band leakage in the Linear Phase filter of r8Brain… although it seems to have less capabilities of parametric control, there are dynamic synergistic filter element relationships that are commonly associative, working in concert with a single control… Pre-ringing may or may not be imbued in the master encoding…
The SoX implementation in the file conversion application TRAX provides for a far more extensive suite of filters/parameters…
The primary concern is in the processing latency, where this becomes transparent to the User… For example, file conversion in PGGB takes a lot of CPU horsepower and the processing time is unacceptable in the context of Audirvāna playback. ![]()
We can up-sample/convert all of our files offline in a sample-rate conversion program like PGGB or others like TRAX and never use the up-sampling algorithms in Audirvāna, this may be impractical for folks with very large libraries…
I decimate my DSD files (except binaural) in DSD Master, to DXD 24/352.8kHz for HRTF processing in the Audirvāna plug-ins module before modulating the DXD file to 5.6MHz (DSD128)
![]()
![]()
![]()
![]()
![]()
1 Like
My SSD isn’t the solution. Whatever the reason I don’t know, but Audirvāna is suffering from the connection to my laptop. A high singing tone is audible when the SSD is attached and when playing music. Maybe the SSD isn’t functioning optimal anymore.
Lowering the buffer didn’t change the behaviour. During all the fiddling AS started showing the same behaviour with SoX. So I have rebooted the laptop, and for the moment AS is playing fine with r8Brain as well.
1 Like
I still suggest lowering your playback pre-load buffer RAM allocation ![]()
I have a software engineering background. While my understanding of the mathematical filter implementations has increased somewhat over 10 years of using Audirvana, I have concluded that I trust my ears more than a theoretical “optimal curve”. But it does help to understand what each upsampling option does, so we know what to listen for when we try to optimize our system for more musical sound:
In my view any filter is a compromise. While Mr. Nyquist was right in proving that any waveform can be perfectly digitally represented using double the maximum frequency, this didn’t mean that Sony and Philips’ decision to pick 44.1 kHz as the sample rate (more than double the human frequency hearing limit of 20kHz) meant that we suddenly had perfect music reproduction. One issue is that if any frequency above 22kHz remains in the signal, it causes distortion because the mathematical (digital) representation has no “room” for it. This means that bits in the hearing range are changed instead. In other words: the “dirt” in the “illegal” frequencies is “folded back” into the signal and distorts frequencies that we can hear very well.
So anything above 20kHz should ideally be filtered out completely. An issue in doing this, is that such a “steep” filter (with only the “room” between 20 and 22 kHz) causes its own side effects. The less steep the filter, the “easier” it is to filter without such negative effects. Many Audirvana users (and many DAC designers) accept that it may be better to start filtering at a lower frequency. Thus the “% of Nyquist” setting of the upsamplers. This means that the filtering can start earlier, be less steep.
By upsampling first, the “illegal” frequencies are also doubled (or more), i.e. moved higher into the spectrum. This gives the filter double (or more) “room” to work on. This is “easier”. And partly explains why many people hear better sound with upsampling enabled: Audirvana then does a better job than the DAC itself.
Another factor is that the actual upsampling costs processing time. The better the filtering, the more powerful the chip required. This is one reason why Audirvana sounds better than many DACs: Our computer has a much more powerful (Intel or Apple) chip than the chips or circuits built into most DACs.
About the graphs
The Impulse graphs show some of the effects on waveforms of applying the mathematical filters used by Audirvana, based on third party algorithms called SoX and r8brain. Ideally, the waveforms have no “preceding” nor “trailing” waves. They should only show one elliptical curve. Nothing before or after it. But one “side effect” of most filters is that they cause “pre-ringing” or “post-ringing”. Many people feel that post-ringing sounds more “natural” and thus subtracts less from musical enjoyment. But to eliminate pre-ringing, one effect of filters is that this causes a timing shift that is frequency dependent: the “phase” changes.
If I understand it correctly, the “phase” graphs show how the timing becomes “off” from frequency to frequency. Arguably, a less “steep” curve might sound more natural. On the other hand, our hearing is much more timing-sensitive at high frequencies. Which explains why many users prefer a “Linear Phase” filter that corrects the timing accross all frequencies. But at the expense of the more “natural” wave forms.
How I interpret the graphs
As I noted above, I’m not sure they help me in optimizing my system. They help me “visualize” the effects of the filters. And they help me understand why I ended up somewhere between “Min. Phase” and “Linear Phase”. But I got there by careful listening. Not by looking (or even understanding) the actual math.
I wrote the above without consulting AI. But, where some others object to using AI, I have asked AI questions on what to listen for while changing the upsampling settings. Sometimes a change affects frequency response (“freshness”), sometimes it affects “cleanliness” versus “distortion/smearing”. Each setting affects the others too. After all, there are only so many bits to work with. Bits that theoretically recreate perfect waveforms, but in practice do not. At least not with 44.1kHz sampled music. But with the upsamplers included in Audirvana, we can get pretty darn close. I now have many tracks that I find to sound almost as good as actual high-res recordings and SACDs.
Oh, and if you prefer not to consult with AI: there is nothing wrong with the articles on Audirvana’s site. Do realize that SoX and r8brain are used elsewhere, too. I find AI to be a very useful tool to help me expand my understanding. It made my latest optimization round easier than those I performed when I was just relying on Google, “the manual” and forum discussions. All of which still have value.
2 Likes
I did ![]()
1 Like
Thanks, I will give this a more thorough read and do some more research and testing when work and family business duties don’t call as much as they do during weekdays… ![]()
1 Like
It is refreshing to have your humanized perspective and insights… We can all pursue more detailed information pertaining to filter design as it applies to digital-audio reproduction and the influential consequences on the signal that we ultimately perceive… I have compiled a larger than average library of research and technical documentations over the years, without the assistance of AI… It will not find anything of consequence that I have not already accumulated and may be drawing from some of my technical communications… It is a good option for complex calculations in some specific case…
Letting your humanness predominate in these discussions gives more credence to your contributions, from my ancient point of view. ![]()
This started my journey in Digital Audio when it was released in English in 1983:
The Sony Book of Digital Audio Technology (first edition).
Time is limited. And sorry to say it: Unless we are the developers of the algorithms (and Audirvana’s upsampling code), it is very likely that AI is going to base its input on more information than I have. To collect the information from traditional sources (including Audirvana’s fine documentation or Google) took me much more time. In fact it took a decade.
I therefore prefer to run my observations and statements through AI before posting. When AI comes up with something new, I often research that deeper. And yes, it is very important to double-check any source including AI.
Here’s why I embrace AI. You are entirely free not to use it:
Below is what AI would have made from my input. And what I would have used if I had posted a review. I personally think it is better language. It also came up with relevant suggested additions to my answer. Some of these suggested additions are because AI has my complete reviews and audition histories. It automatically takes my personal experiences into account. But it also automatically detects where one of my inputs would benefit from further explanation.
AI suggested addition 1:
(… This means that bits in the hearing range are changed instead. In other words, the “dirt” in the “illegal” frequencies is “folded back” into the signal and distorts frequencies that we can hear very well.)
This phenomenon is called “aliasing” and it’s why anti-aliasing filters are so important in digital audio. The steeper the filter’s roll-off, the more effectively it prevents these unwanted frequencies from causing problems in the audible range.
AI suggested addition 2:
An impulse response essentially shows what happens when you feed a theoretical perfect spike (impulse) into the filter. In a perfect world, you’d get the same spike out. In reality, filters create ripples before and/or after the main spike.
AI suggested addition 3:
Phase response is crucial because it affects how different frequencies align in time. Linear phase filters maintain the same timing relationship between all frequencies, which can preserve spatial cues and instrument positioning. Minimum phase filters allow different frequencies to shift in time relative to each other, which can sometimes sound more natural for transients but might affect imaging precision.
AI suggested addition 4:
One thing I’ve found helpful is to listen for specific elements when adjusting these settings: spatial cues (like reverb tails and instrument positioning), transient attacks (piano strikes, percussion), and the natural decay of sounds. These aspects seem particularly sensitive to phase and impulse response characteristics.
AI version of my full response:
Having worked with Audirvana for over a decade with my software engineering background, I’ve come to realize that while understanding filter theory helps, ultimately I trust my ears more than any “perfect” mathematical curve. That said, knowing what each upsampling setting actually does helps us listen for specific changes when tuning our systems.
Digital audio filtering is always about tradeoffs. Yes, Nyquist proved we can theoretically represent any waveform by sampling at twice the highest frequency, which is why 44.1kHz was chosen for CD audio (exceeding twice our roughly 20kHz hearing limit). But real-world implementation is messier.
The primary challenge is that any frequencies above 22kHz in the original signal cause aliasing - they “fold back” into the audible range as distortion because there’s no mathematical space for them in the digital representation. These artifacts can make music sound harsh or unnatural.
The traditional solution is filtering out everything above 20kHz, but very steep filters create their own problems - mainly time-domain distortions that affect how natural music sounds. This is why many audiophiles and DAC designers prefer gentler filters that start rolling off earlier (the “% of Nyquist” setting in Audirvana’s upsamplers).
Upsampling helps because it moves these problematic frequencies higher in the spectrum, giving filters more “breathing room” to work with. This often results in better sound than relying solely on your DAC’s built-in filtering. Plus, your computer’s processor is typically much more powerful than the chips in most DACs, allowing for more sophisticated filtering algorithms.
The impulse and phase graphs visualize different aspects of filter behavior. An impulse response shows what happens when you feed a perfect spike into the filter. Ideally, you’d get the same spike out without any additional ripples. In reality, filters create “ringing” - ripples before the spike (pre-ringing) or after it (post-ringing).
Many listeners find post-ringing more natural-sounding because it mimics how acoustic events occur in nature - nothing in nature makes sound before an event happens. However, minimizing pre-ringing creates frequency-dependent timing shifts, shown in the phase graphs.
Phase response shows how different frequencies are time-aligned. Linear phase filters (flat horizontal line on phase graphs) keep all frequencies perfectly time-aligned, which can preserve spatial cues and instrument positioning. Minimum phase filters allow timing to vary with frequency, which can sound more natural for transients but might affect imaging precision.
My own sweet spot landed at 66% between minimum and linear phase after extensive listening tests. The graphs help me visualize what’s happening, but they didn’t determine my settings - careful listening did.
When adjusting these parameters, I listen specifically for:
- Spatial cues (reverb tails, instrument positioning)
- Transient attacks (piano strikes, percussion)
- Natural decay of sounds
- “Freshness” versus smearing
- Overall emotional engagement
With properly optimized upsampling settings, many of my 44.1kHz tracks now sound remarkably close to high-resolution recordings and SACDs - proof that the theory really does translate to better musical enjoyment when applied thoughtfully.
The inevitability is that AI will be incorporated in the player architecture so that simple user profile information will accommodate individual aesthetic in the contextual environment in which the player is operational… All feedback will be automated. ![]()
I’ll revisit this as soon as I get a chance
We got the point about the AI thing, let it lie
AI has absolutely no way of hearing what you or I hear. Nor can it know what gives us goosebumps and what doesn’t. It can only learn from our experiences. And then help us by aggregating that knowledge.
One of my favorite things that Steve Jobs said:
“Always hire people who are smarter than you.”
That has also helped me in my career, resulting in some of the money I now spend on improving my enjoyment of my music system. Including the monthly payment to Audirvana itself ![]()
It doesn’t need to have the same hearing neural-physiological capability, it can determine this through the acquisition of preferrential personal aesthetics via a myriad of input streams… a simple one is understanding your musical preferences. ![]()
It can rationalize this from both the musical tastes and with simple auditory analysis like Apple is already doing this with AirPods Pro… At some point making the decision to up-sample or not, will become moot… this is something that is intrinsically tied to the evolution of digital-audio production in concert with computer capabilities… When everything is produced at high sample-rate like DSD256 most will never need to make any determinations in regard to technology… only how to simply achieve an aesthetically pleasing sound quality for them individually.
Well, if it gets to the point where Audirvana can automatically configure its upsampling settings to get immediate maximum musical enjoyment, I would not object to that at all. I don’t mind spending time on optimization. But once I’m happy, I prefer to enjoy the system for years and not worry about the technicalities. I’m active on the forum now because I’m in an optimization process. But over the years I’ve also been away for long stretches. I’m now at the point where I can feel I can actually contribute with actual experiences that are useful for others. As I have shared in other posts, initially I only heard differences with quite coarse adjustments. It is the feedback from countless others that has pushed my system forward.
1 Like
So it is for all active listener audiophiles… ![]()
![]()